[Paper Review] UMT (Unified Multimodal Transformers)
Published:
Introduction
Video highlight detection and video moment retrieval are closely related tasks, often discussed in similar contexts. However, there has been a lack of unified models that explicitly address both. Traditional models such as Moment-DETR assume the presence of a text query, limiting their generalizability and highlighting a lack of true multimodal reasoning.
Unified Multi-modal Transformers (UMT) address this limitation. When a text query is available, UMT uses it as a hint for highlight detection. When absent, UMT relies solely on video and audio modalities to identify key moments, thereby supporting both query-based and query-free settings.
Method
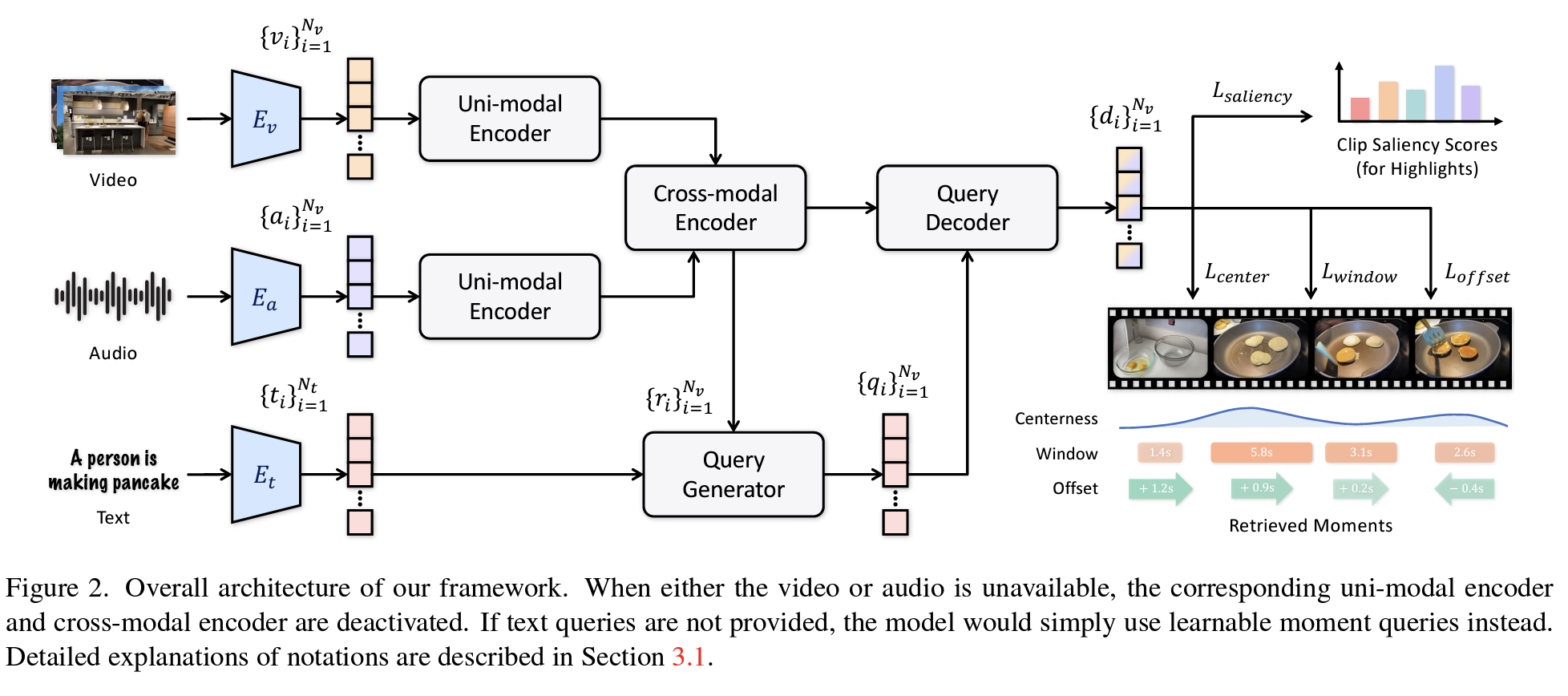
The core contribution of UMT lies in its ability to understand videos through both visual and auditory modalities using a unified encoder. Furthermore, it optionally integrates text queries to refine highlight criteria.
Uni-modal Encoder
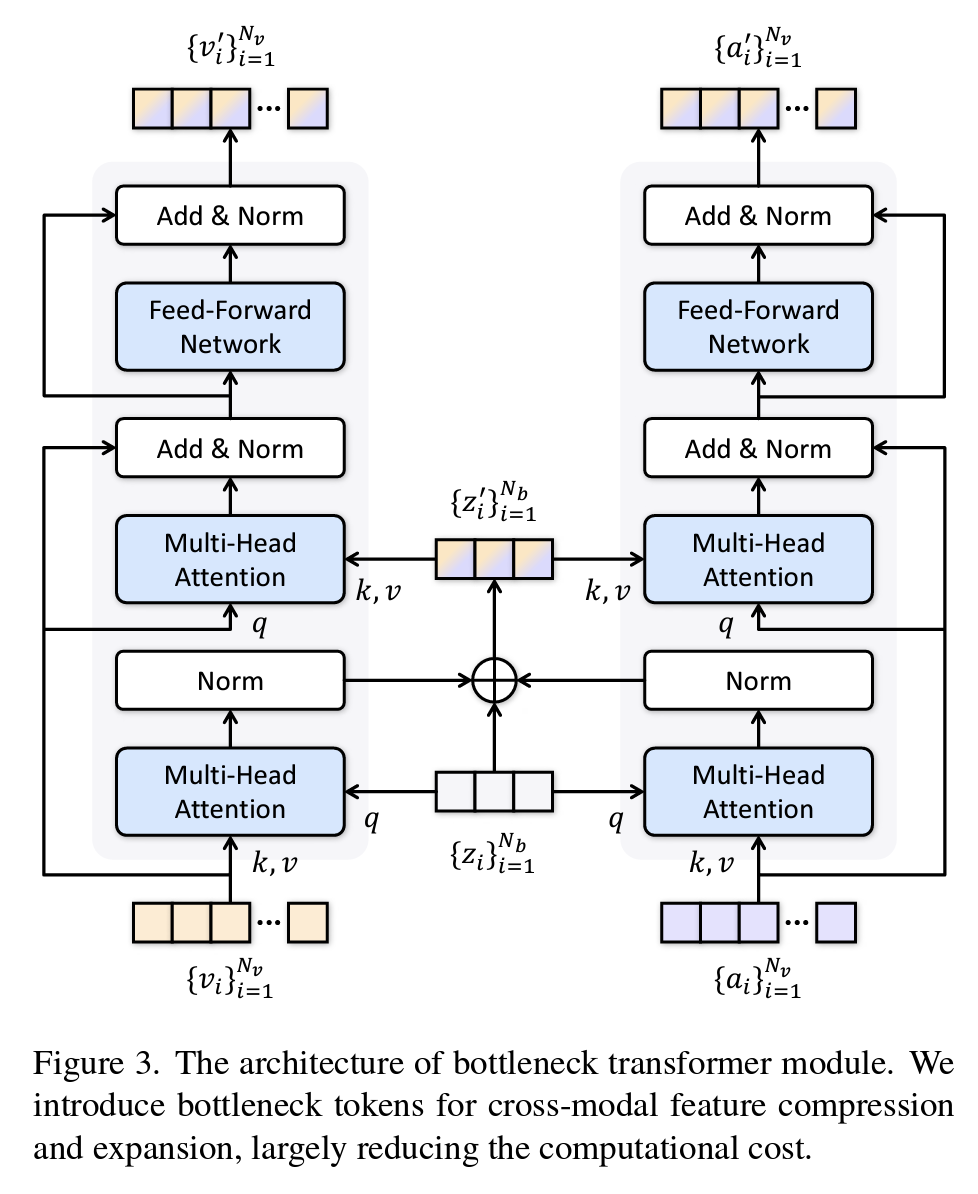
While visual and auditory signals are encoded separately at first, UMT introduces bottleneck tokens to unify and compress cross-modal features. These tokens act as summary checkpoints, reducing the cost of exhaustive attention computations over long sequences. Rather than performing full attention over all frames, the bottleneck tokens retain crucial temporal context.
Cross-modal Encoder
Feature Compression
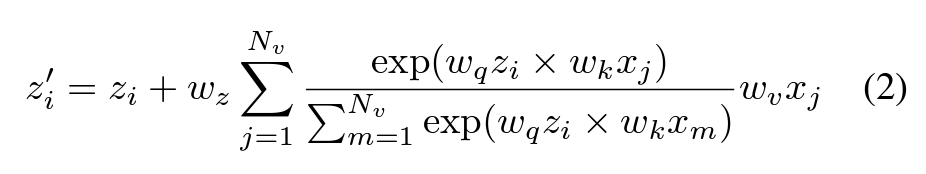
Let $z_i$ denote bottleneck tokens encoding compressed multi-modal representations. These serve as compact queries within the attention mechanism, replacing full-scale token matrices.
Feature Expansion
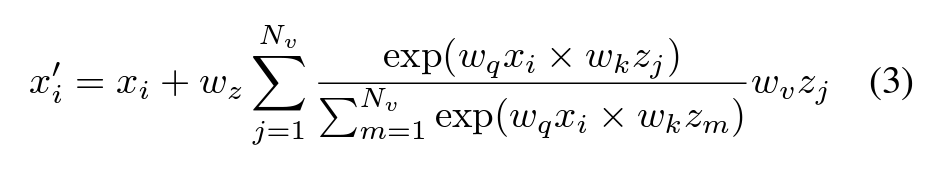
To apply the compressed knowledge during prediction, bottleneck tokens are expanded again. The combined visual-audio information, enriched by this process, is passed to a feedforward network for further reasoning.
Query Generator
Natural language sequences differ in length from video frame sequences, making direct alignment difficult. UMT addresses this by using:
- K, V from the text query features
- Q from joint visual-audio representations
This setup enables UMT to calculate attention weights between each video clip and the semantic content in the query, learning to infer the relevance of clips to text descriptions.
Query Decoder & Prediction Heads
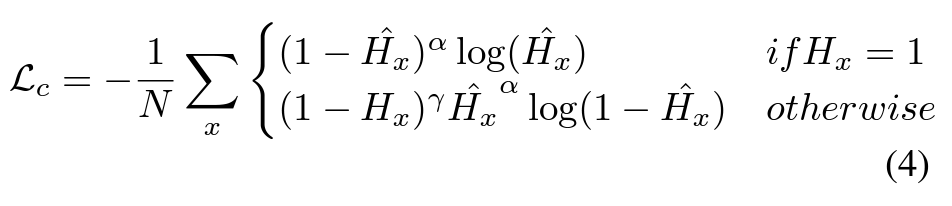
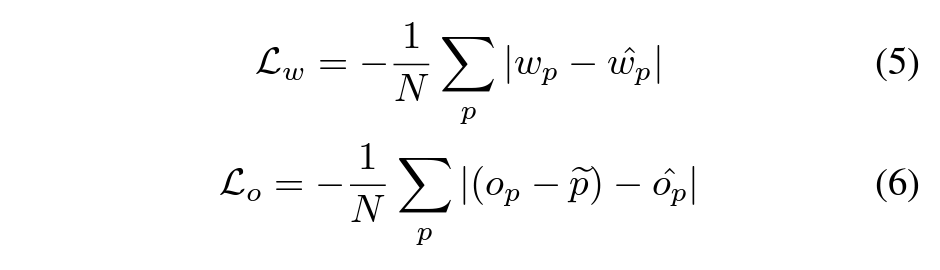
Centerness
Measures how close the predicted highlight is to the central theme of the video. A 1D Gaussian kernel over the temporal axis helps define importance distributions:
$C(t) = \exp\left(-\frac{(t - \mu)^2}{2\sigma^2}\right)$
Window
Assesses whether the predicted highlight length aligns with the ground truth. Overestimation or underestimation of duration is penalized.
Offset
Represents the temporal deviation between the predicted and actual highlight location. For example, a predicted start time 5 seconds early would yield an offset of $+5$ seconds.
Weighted Sum of Losses
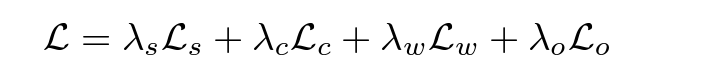
All individual loss components—centerness, window, and offset—are aggregated via weighted sum. However, the rationale for the choice of weights is not clearly justified in the paper.
Experiments

UMT demonstrates strong performance in both query-dependent and query-independent video understanding benchmarks, outperforming baselines across tasks.
Limitations & Discussion
Subjectivity of Highlights: The concept of “highlight” is inherently ambiguous. Depending on the viewer’s intent or the query context, interpretations of the video’s central content can vary greatly.
Audio Understanding: The model’s use of audio is limited to low-level representations. In cases where linguistic understanding from speech (e.g., interviews) is necessary, the uni-modal audio encoder may be insufficient. UMT appears to model audio more as an ambient class (e.g., music vs. noise) rather than extracting and reasoning over speech content.
Conclusion
UMT introduces a flexible and unified framework for video understanding, capable of handling both multimodal inputs and variable query conditions. Its design, particularly the use of bottleneck tokens and the query generator-decoder setup, offers promising directions for efficient and generalizable video analysis.
Further work may enhance audio-language alignment and incorporate explicit speech recognition to better leverage audio in semantically rich scenarios.