[Paper Review] Segment Anything Model 2 (SAM2)
Published:
Introduction
Unlike static images, videos require reasoning over spatio-temporal extents—object appearance changes across time and interactions with the scene evolve. SAM2 tackles this challenge by extending promptable visual segmentation (PVS) to video, powered by a memory-based mechanism that maintains and updates object representations across frames.
- SAM2 integrates memory modules that store object features and interaction history from previous frames.
- In static images, the memory remains empty, and SAM2 naturally reverts to SAM behavior.
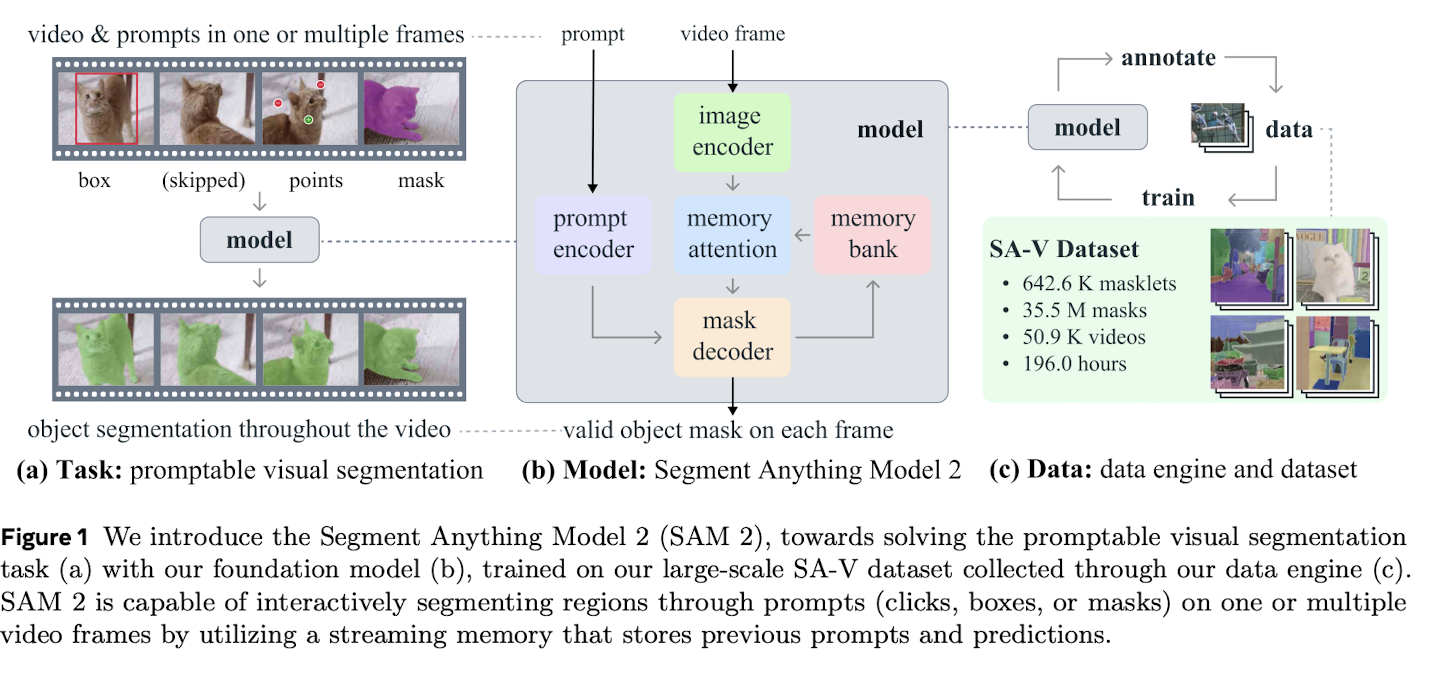
Beyond architecture, SAM2 introduces a data engine designed to build a generalized segmentation dataset through semi-automatic annotation. Unlike previous segmentation datasets that only include full object classes, SAM2 allows finer-grained labels such as parts or subparts (e.g., a dog’s tongue).
Related Work
Relevant domains include:
- Image Segmentation (e.g., SAM)
- Interactive and Semi-supervised Video Object Segmentation (VOS)
- Dataset construction for fine-grained object understanding
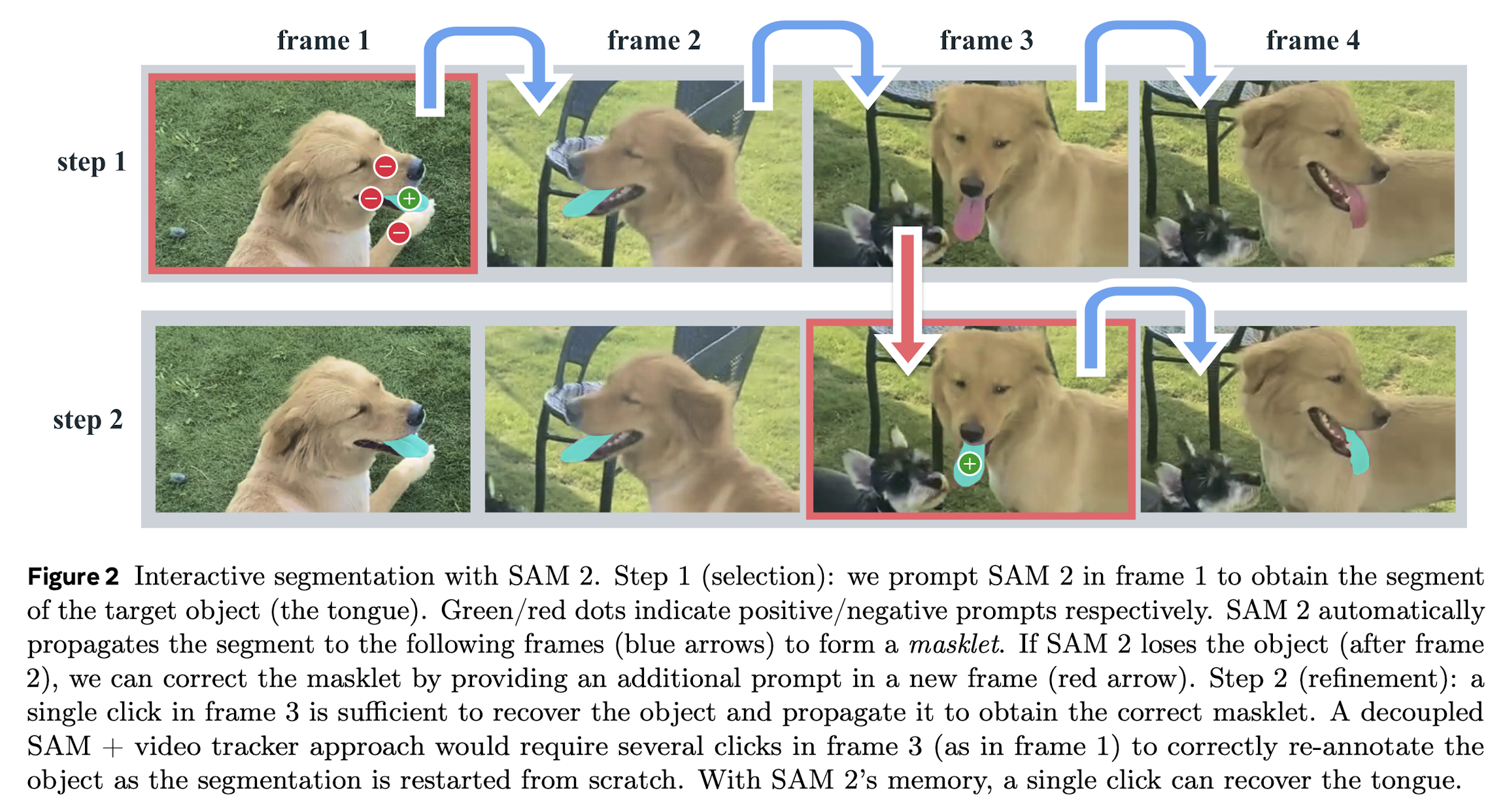
SAM2 supports part-level segmentation by treating prompts as flexible and resolving ambiguities in object boundaries.
Task: Promptable Visual Segmentation (PVS)
SAM2 follows the prompt-based segmentation paradigm from SAM, supporting multiple prompt types:
- Positive/Negative points (clicks)
- Bounding boxes (bboxes)
- Reference masks
These prompts can be used to:
- Select new target objects
- Refine or correct segmentation
Evaluation settings include:
- Online/offline multi-frame video segmentation with varying prompt frequency
- Semi-supervised VOS (only first-frame label provided)
- Image segmentation (SA benchmark)
Model Architecture
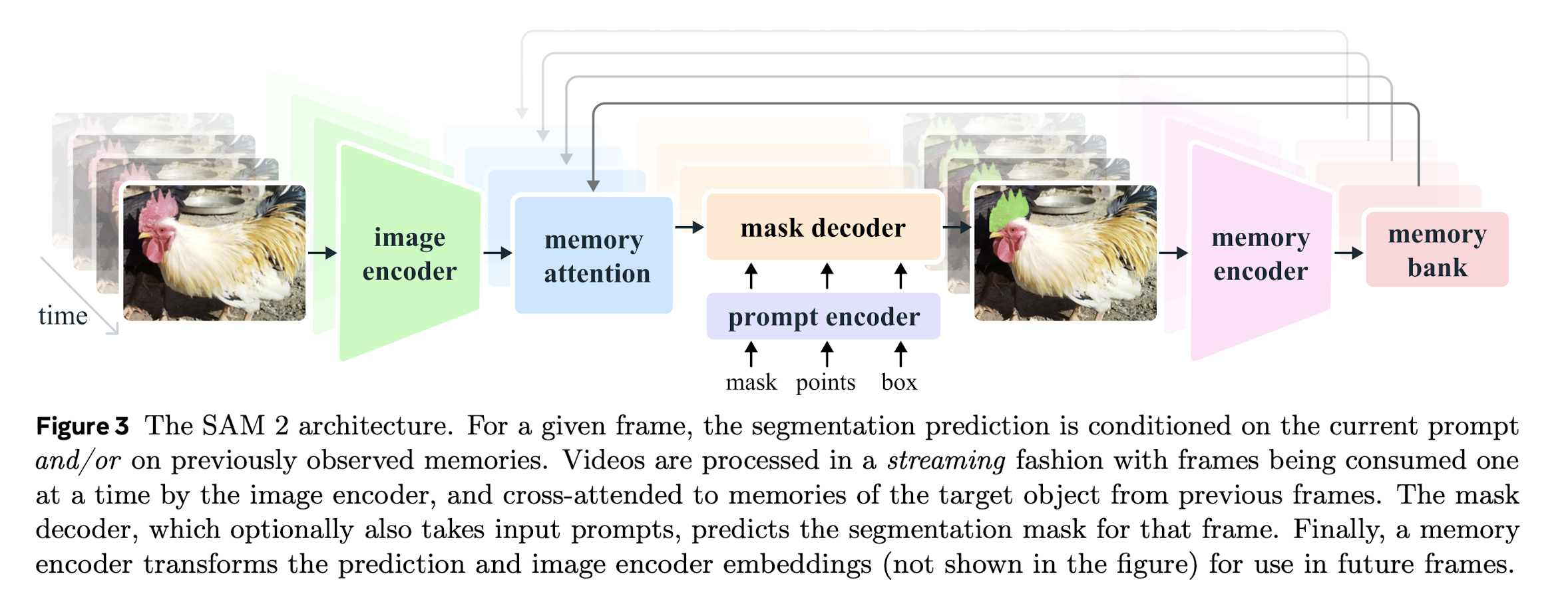
At its core, SAM2 performs single-frame segmentation and extends it over time using memory. The decoder receives two types of frame embeddings:
- Prompted frame embeddings from the current or future frames
- Memory embeddings from past predictions stored in the memory bank
These embeddings are jointly attended to and used to predict the mask for the current frame.
Image Encoder
SAM2 uses a Hiera (hierarchical MAE-pretrained) encoder to generate multi-scale image features:
- These are unconditional tokens $\phi(x_t) \in \mathbb{R}^{N_t \times d}$, where $N_t$ is the number of patches in frame $t$.
- Hierarchical encoding allows capturing both coarse and fine image structures.
Memory Attention
For a current frame $x_t$, its representation $\, z_t = \phi(x_t) \,$ is updated by attending to previously stored frames ${z_{t-k}}$ and their associated object masks ${m_{t-k}}$.
The conditioned embedding is computed via:
\[\tilde{z}_t = \text{Attention}(z_t, [z_{t-1}, z_{t-2}, \ldots], [m_{t-1}, m_{t-2}, \ldots])\]Internally, this consists of self-attention among $z_t$ and cross-attention with memory tokens.
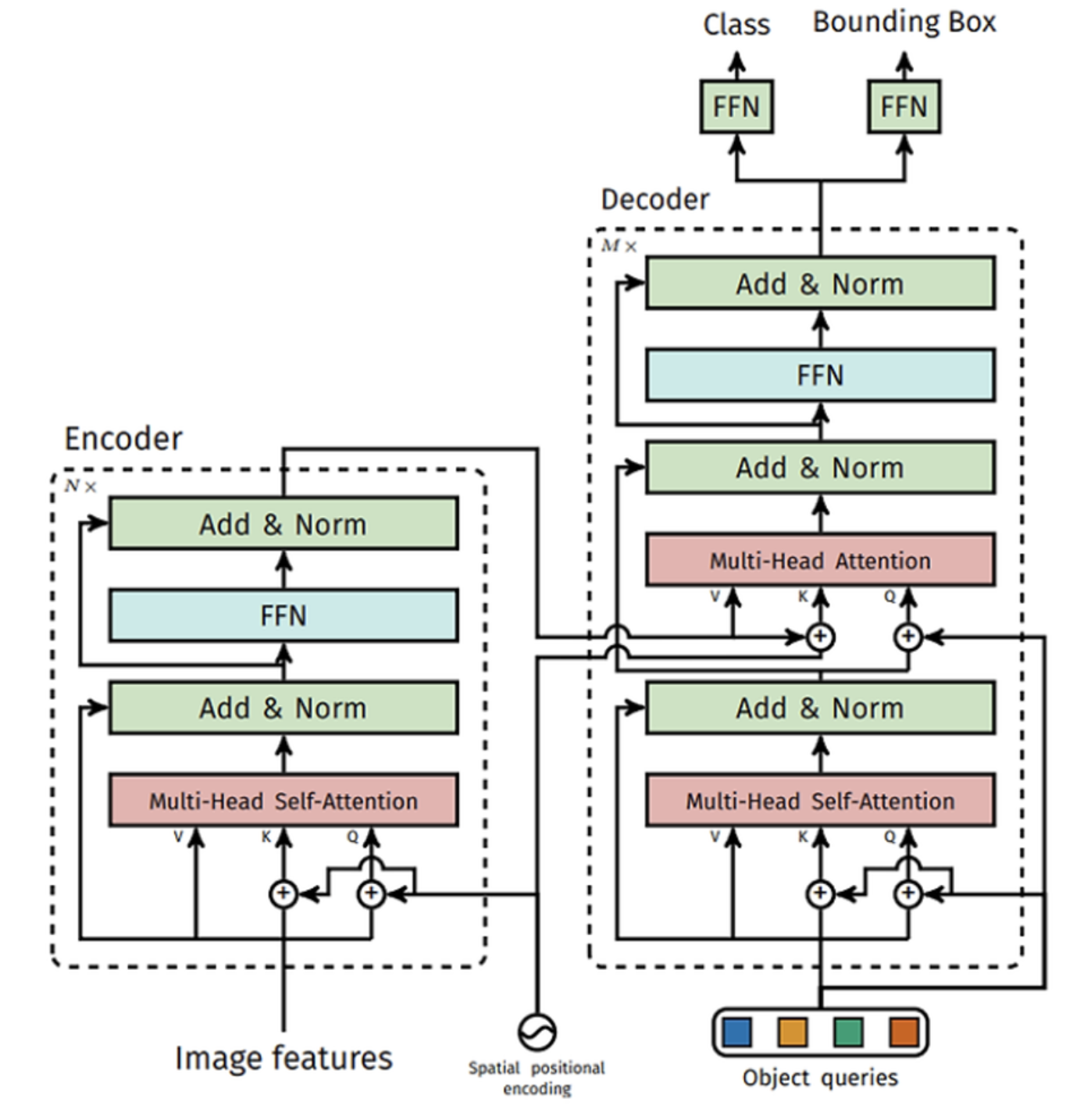
Prompt Encoder & Mask Decoder
SAM2 inherits the two-way transformer architecture from SAM, which updates both the prompt and image embeddings iteratively:
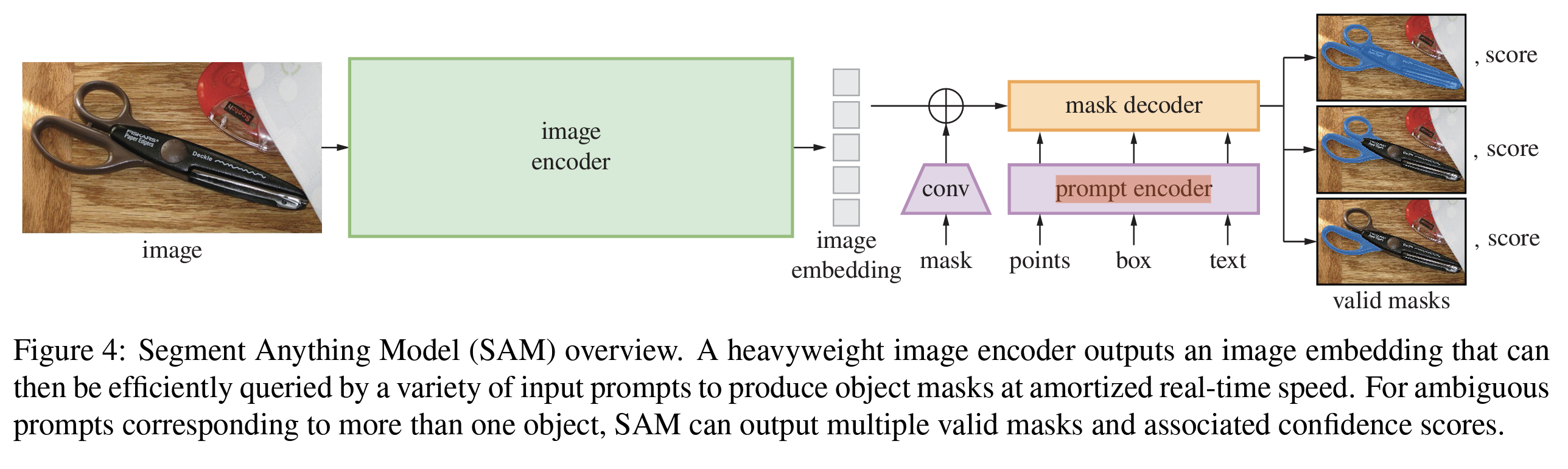
- Prompts that are spatially ambiguous generate coarse masks
- A fallback mechanism selects the most confident (IoU-maximizing) mask
- SAM2 also predicts object presence, allowing for null masks when no object exists in the frame
- Skip connections from the encoder directly enhance the final mask quality
Memory Encoder
Memory encoding combines:
- Downsampled predicted masks $m_{t-1}$
- Corresponding frame embeddings $z_{t-1}$
These are added elementwise and passed through convolutional layers to form memory tokens:
\[M_{t-1} = \text{Conv}(z_{t-1} + \text{Down}(m_{t-1}))\]Memory Bank
- Memory tokens and prompt frames are stored in FIFO queues
- Object pointers are derived from decoder output and stored separately
- Memory attention uses cross-attention between spatial tokens and object pointers
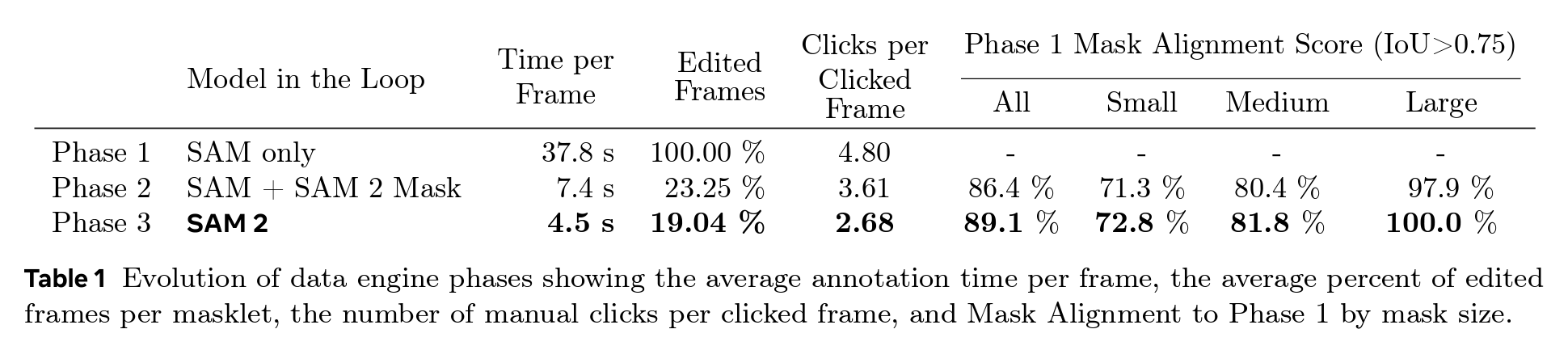
Data Engine Phases
Phase 1: Per-frame SAM
Each frame is independently annotated using SAM:
- No temporal reuse → slow but accurate
- Speed: ≈37.8 sec/frame
Phase 2: SAM + SAM2 Mask Propagation
First frame annotated with SAM, others automatically labeled by SAM2:
- Annotator corrects future frames
- Speed: ≈7.4 sec/frame
Phase 3: Full SAM2 Prompt Loop
All SAM2 prompt types used to initialize and refine masks:
- Annotator edits rather than drawing from scratch
- Speed: ≈4.5 sec/frame
Quality Verification
Masks are labeled:
- “Satisfactory”: accurate, consistent over time
- “Unsatisfactory”: either spatially incorrect or inconsistent → sent back for refinement
Auto Masklet Generation
To ensure diverse annotations, SAM2 auto-generates candidate masks using grid-based prompts on the first frame.
- Satisfactory ones are added directly
- Unsatisfactory ones are sent for manual refinement
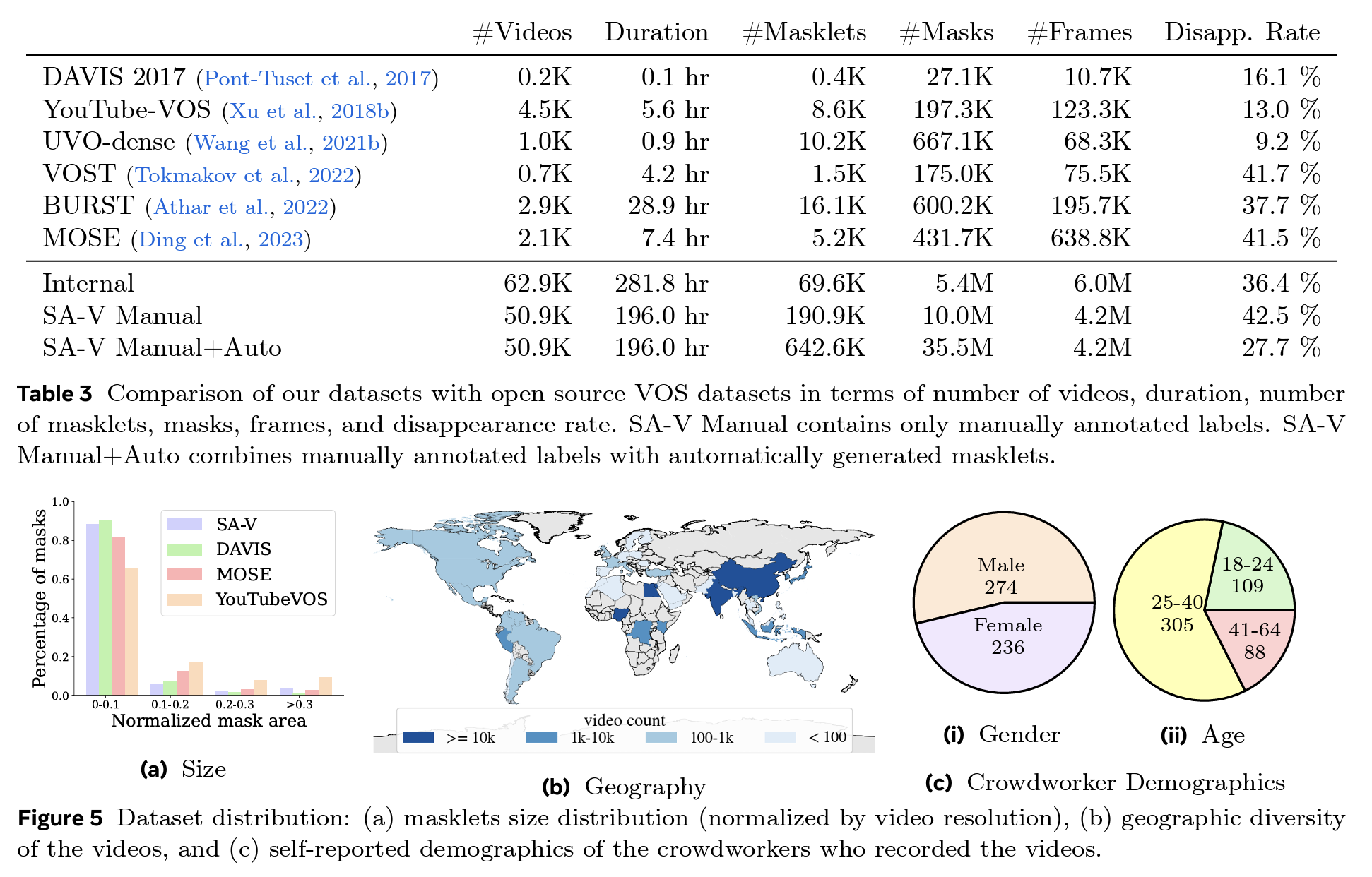
Video Segmentation Tasks
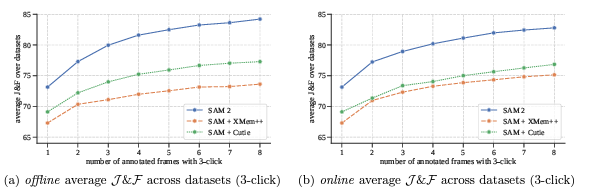
- SAM2 outperforms conventional pipelines like SAM+XMem, SAM+Cutie
- Its memory and object-prompt integration yield better temporal consistency

- SAM2 performs better in object boundary quality and frame consistency, especially under class-agnostic settings
Comparison to SOTA: Semi-supervised VOS
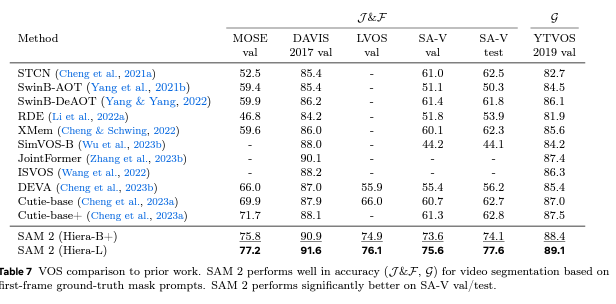
Using Hiera-S and Hiera-B encoders, SAM2 surpasses the best previous semi-supervised video segmentation models in J\&F metrics.
Appendix
1. Memory Encoder & Bank (Appendix C.1)
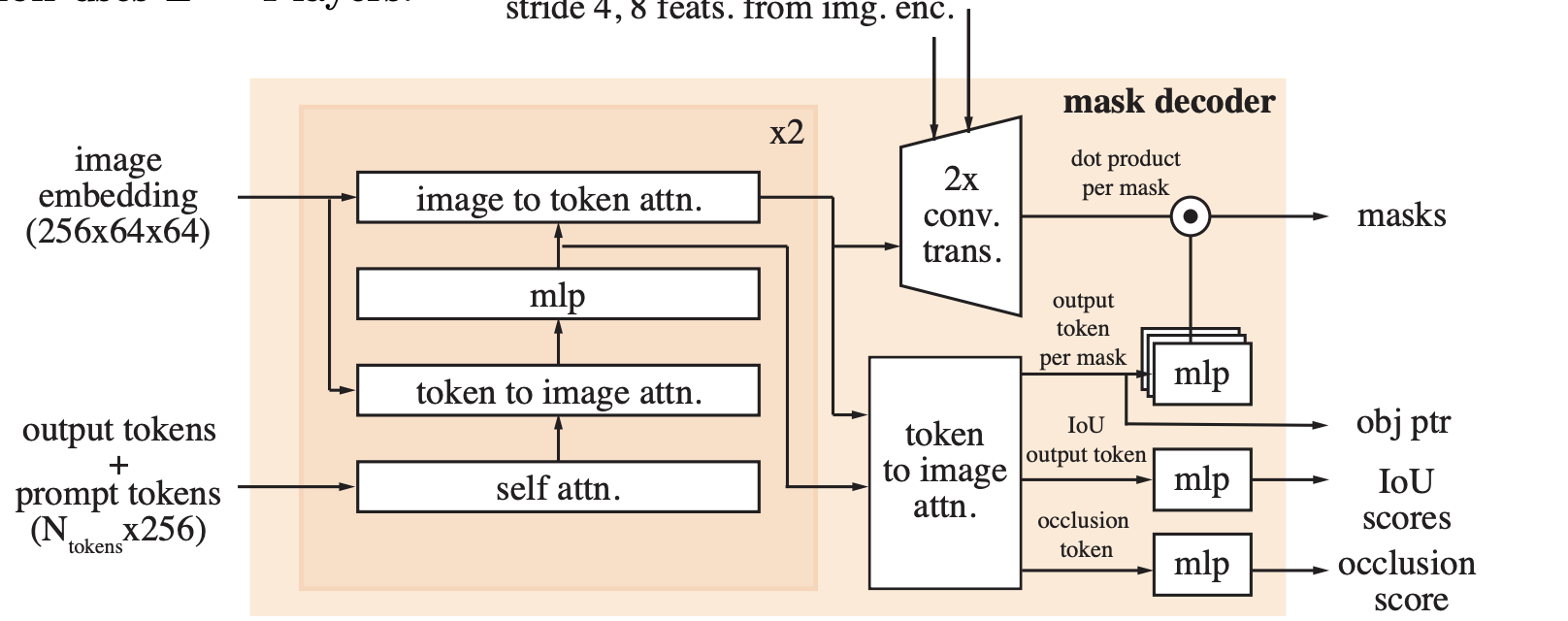
Memory is formed by combining frame embeddings with mask tokens:
\[M_t = \text{Conv}(\phi(x_t) + \text{Down}(m_t))\]- Object pointers come from decoder outputs and represent salient regions for the current frame
- These are used in cross-attention to refine future predictions
2. Model Capacity (Appendix C.2.1)
Scalability tradeoffs:
- Resolution: 512 → 1024 = +4% J\&F, but 4.5× slower
- Frame memory: 4 → 8 = +2% J\&F, negligible speed drop

3. Data Engine Comparison (Appendix D.2.2)
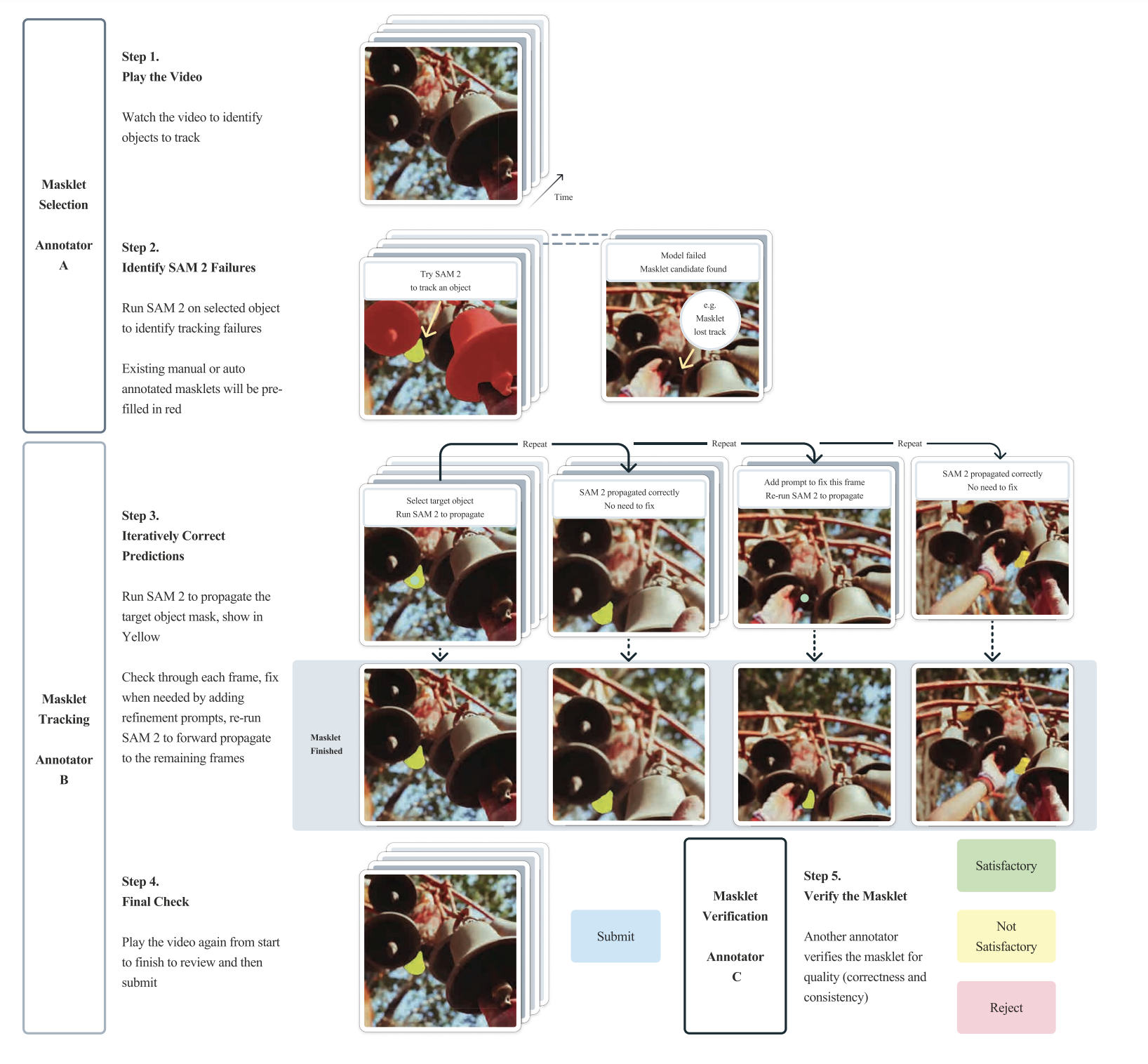
- Phase 3 reduces time to 4.5s/frame (8.4× faster than Phase 1)
- Refined frame ratio drops to 19%, clicks per frame lower
The data engine is key for category-agnostic generalization, preventing overfitting to predefined classes.
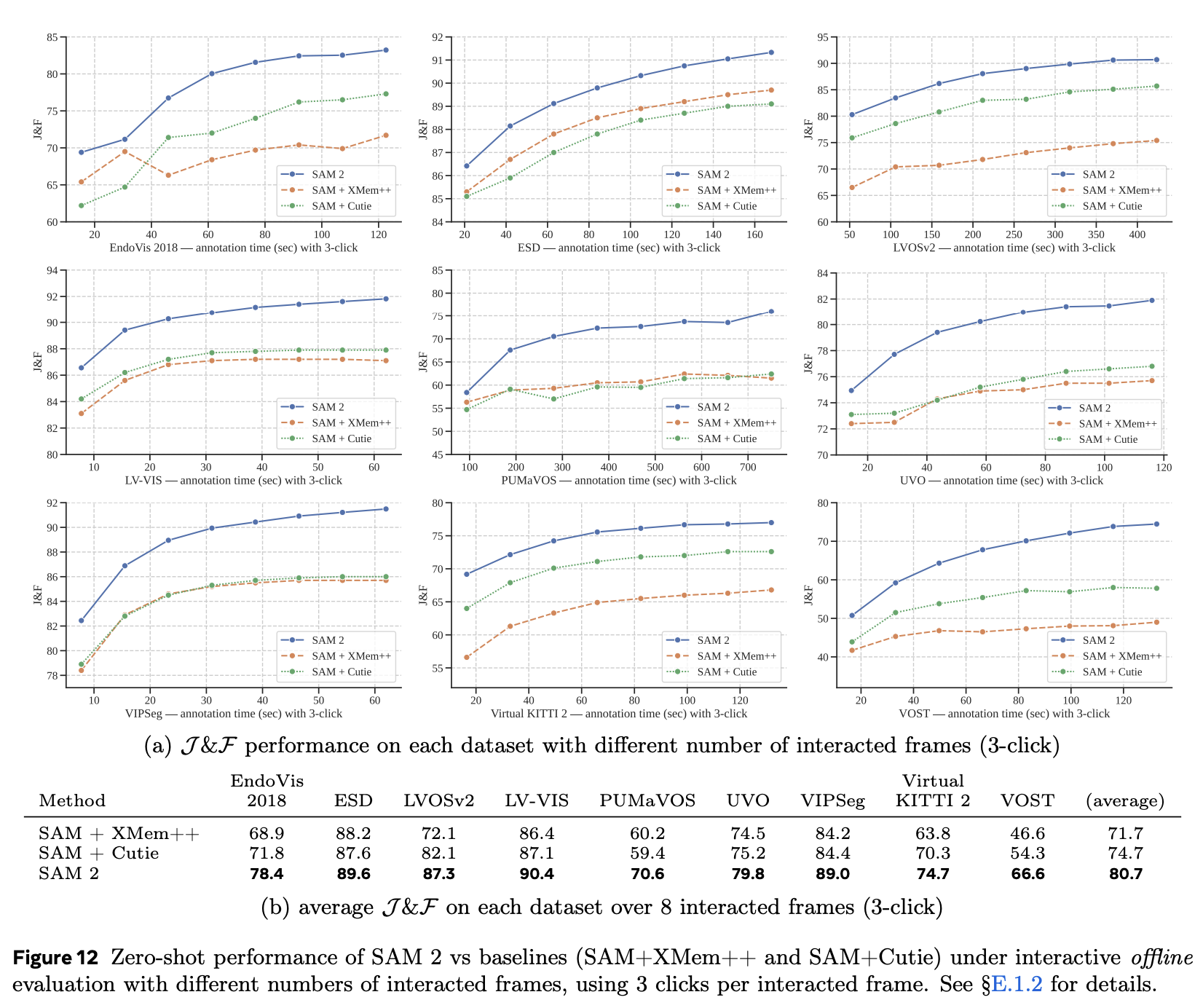
4. Zero-shot Video Tasks (Appendix E.1)
- Achieves 75.4% J\&F with 3 clicks
- Scores 77.6% on zero-shot video datasets with no retraining
Conclusion
SAM2 represents a major leap in promptable segmentation for videos:
- Integrates spatio-temporal memory, improving object tracking over time
- Uses flexible prompts and structured memory to handle occlusion, ambiguity, and absence
- Combines accurate segmentation with efficient annotation pipelines
Through its generalization and high annotation throughput, SAM2 provides a foundation for large-scale, object-centric video understanding.