[Paper Review] End-to-End Object Detection with Transformers (DETR)
Published:
This post is the review of DETR Paper
Citations DSBA Lab’s Youtube video HerbWood Tistory blog
DETR: End-to-End Object Detection with Transformers
Object detection is a task that involves detecting objects within an image and predicting their class and location. Traditional object detection models are divided into two categories: one-stage detectors and two-stage detectors. One-stage detectors, like YOLO (You Only Look Once), are known for their speed and suitability for real-time applications. In contrast, two-stage detectors, such as Faster R-CNN, generally offer higher accuracy but at the cost of speed.
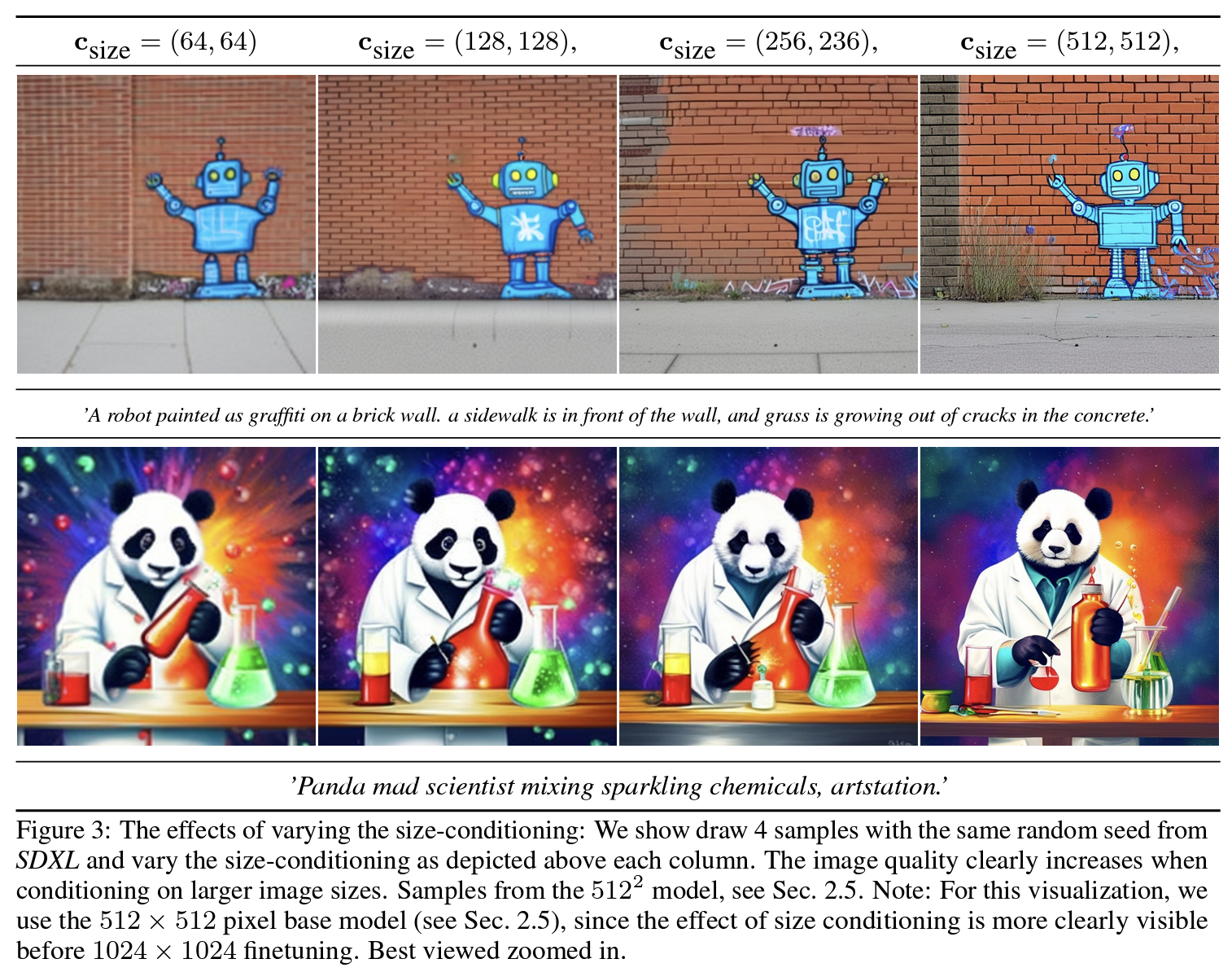
The Transformer model, initially designed for NLP tasks, has been adapted for vision tasks in DETR. DETR leverages the Transformer architecture’s encoder-decoder structure and its ability to learn global information through the attention mechanism. However, unlike Vision Transformers (ViT), which directly input image patches into the encoder, DETR utilizes image features extracted via a CNN.
DETR Network Architecture
Key Differences Between DETR and Traditional Transformers
Feature Map Input
- DETR receives image feature maps from the encoder, whereas traditional Transformers take embeddings from sentences as input. DETR extracts feature maps using a CNN backbone, reduces their dimensions through a 1x1 convolution layer, and flattens the spatial dimensions before inputting them into the encoder. For example, a feature map with height ( h ), width ( w ), and channel count ( C ) is converted to ( d \times hw ) for input, where ( d ) is smaller than ( C ).
Positional Encoding
- Transformers use positional encoding to maintain order within the input sequence due to their permutation invariant nature. DETR generalizes this to 2D spatial positional encoding for feature maps. It applies 2D sine and cosine functions along the x and y axes to derive positional encoding, which is then concatenated channel-wise and added to the input features.
Object Queries
- Instead of target embeddings used in traditional Transformers, DETR uses object queries, which are learnable embeddings of length ( N ).
Attention Mechanism
- Traditional Transformers employ masked multi-head attention during the first attention operation in the decoder to prevent future token information from being used. DETR, however, performs multi-head self-attention without masking since it predicts all object locations in parallel.
Dual Head Output
- DETR has two heads in the decoder: one for predicting bounding boxes and the other for class probabilities, unlike traditional Transformers, which have a single linear layer for predicting class probabilities.
Encoder
The image is converted into a feature map via a CNN, which serves as the input for the Transformer encoder. Unlike traditional CNNs, the encoder can capture global information.
Decoder
The Transformer decoder receives object queries as input, learning to detect specific parts of the image. Positional embedding in the decoder is not meaningful since object queries are independent and parallel, rendering position information irrelevant. Instead, object queries output positional encoding via attention mechanisms.
DETR introduces the concept of Bipartite Matching to match predictions with ground truth objects, optimizing the match using the Hungarian algorithm based on class prediction and box prediction costs.
Loss Function
- Classification Loss
- Measures the difference between the predicted class probabilities and the actual classes using cross-entropy loss.
- Bounding Box Loss
- Measures the difference between predicted and actual bounding box coordinates using L1 loss and Generalized IoU (GIoU) loss. While IoU measures the ratio of overlapping area between two bounding boxes, GIoU introduces an additional term to handle cases where boxes do not overlap, providing a more suitable metric.
Performance Evaluation and Experimental Results
DETR’s performance was evaluated using the COCO dataset, a standard benchmark for object detection models. The key metrics used were Average Precision (AP) and Average Recall (AR).
- Large Object Detection
- DETR excels at detecting large objects due to the Transformer’s global attention mechanism, which captures the overall shape and features of large objects. DETR outperformed Faster R-CNN in AP for large objects.
- Small Object Detection
- Performance on small objects was relatively lower. This is attributed to the CNN’s inability to effectively capture features of small objects and the Transformer’s limitations in learning multi-scale features.
- Training Time
- DETR required longer training times compared to Faster R-CNN due to the slow convergence of the attention mechanism in the early stages. However, inference time was relatively shorter.
- Reduced False Positives and Negatives
- The introduction of Bipartite Matching allowed for unique, one-to-one matching of object queries to actual objects, reducing the rates of false positives and negatives, thereby improving overall accuracy.
Conclusion
DETR represents a significant advancement in object detection by leveraging the strengths of Transformer architecture. While it shows superior performance in detecting large objects and offers a novel approach to matching predictions with ground truth, challenges remain in optimizing its performance for small objects and reducing training times. The incorporation of Bipartite Matching and the dual-head decoder architecture are notable innovations that contribute to its accuracy and efficiency.